mydata <- tibble(
id = 1:4,
grade=c("9th","10th","11th","9th")) %>%
mutate(grade_fac = factor(grade))
levels(mydata$grade_fac)[1] "10th" "11th" "9th" STAT 220

ca10-yourusername repository from Github10:00
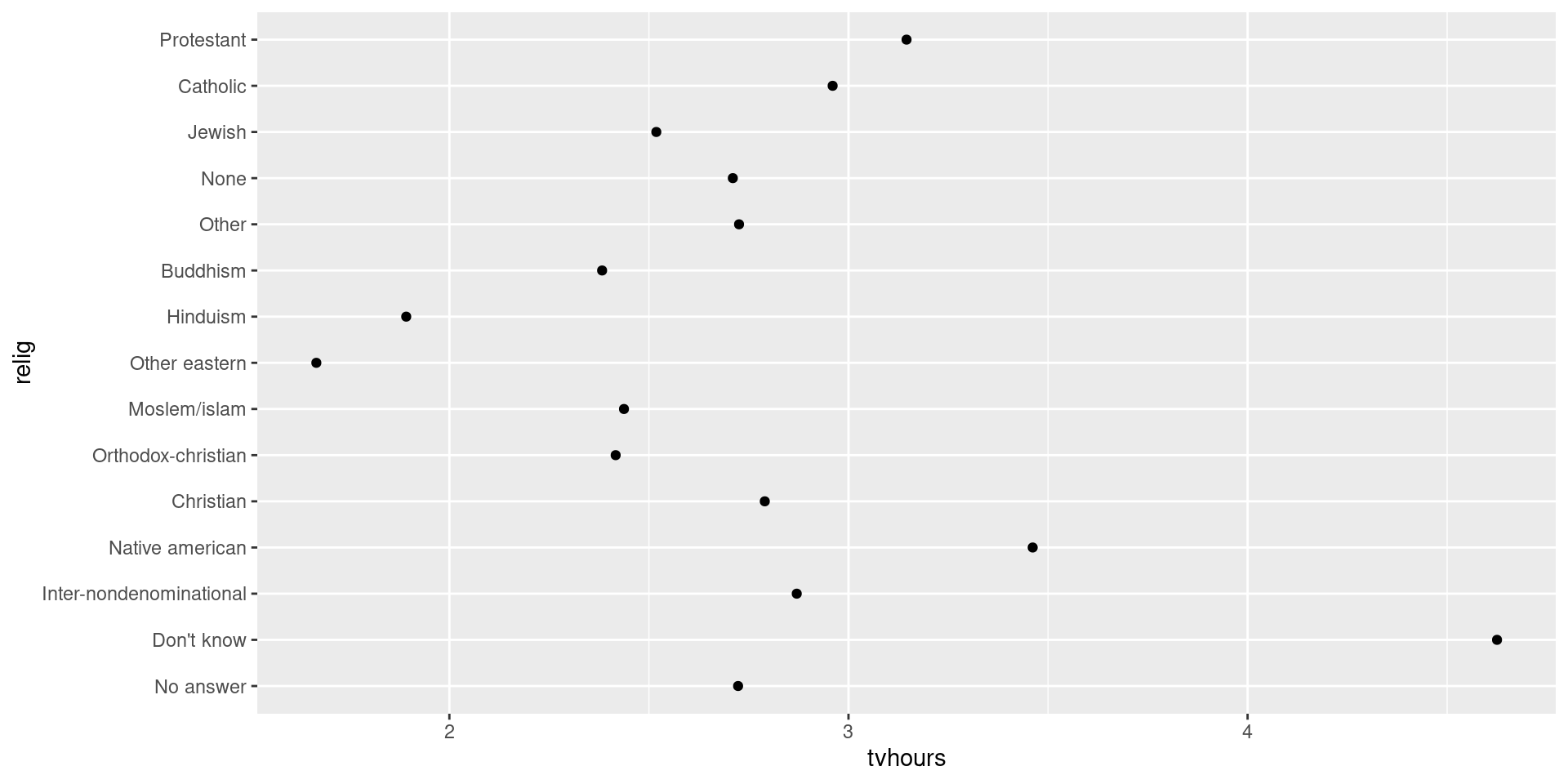
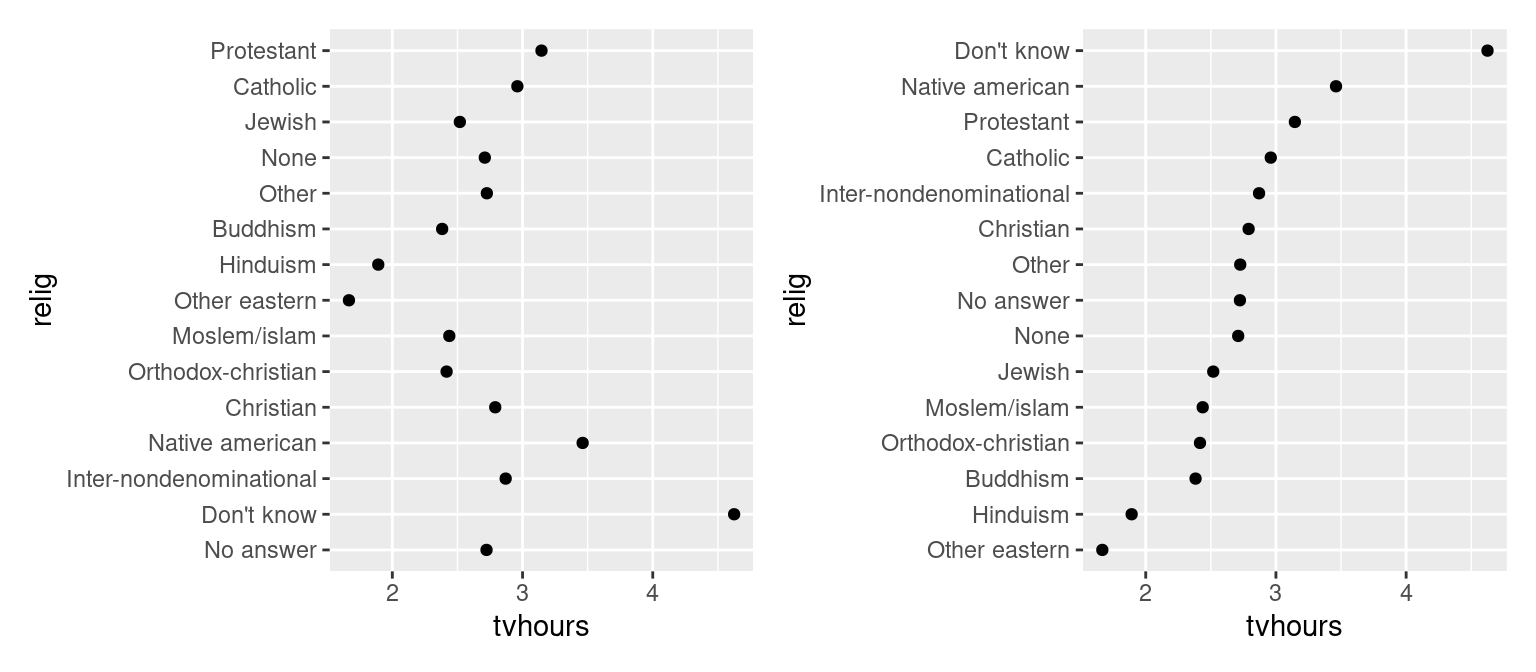
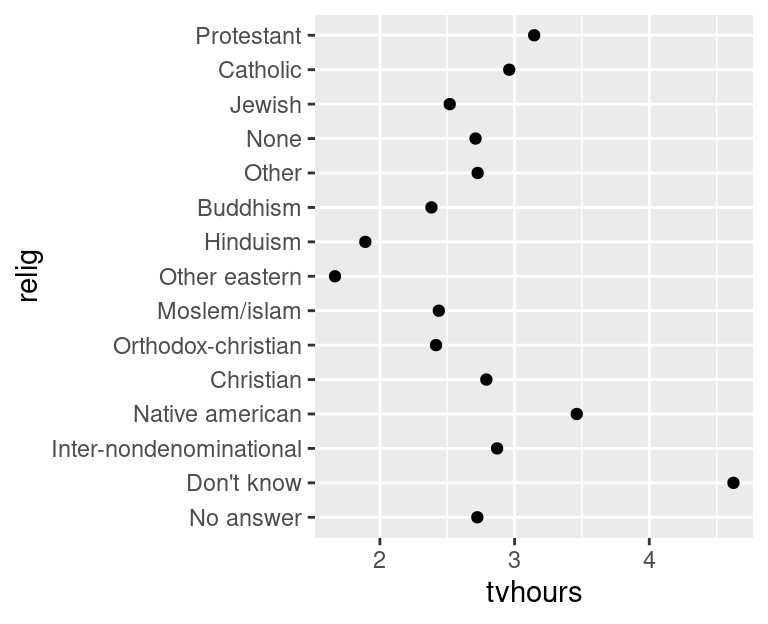
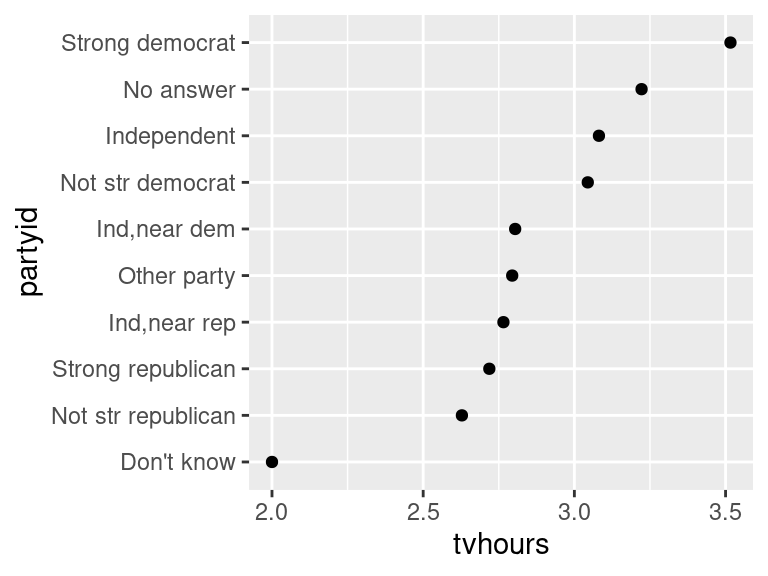
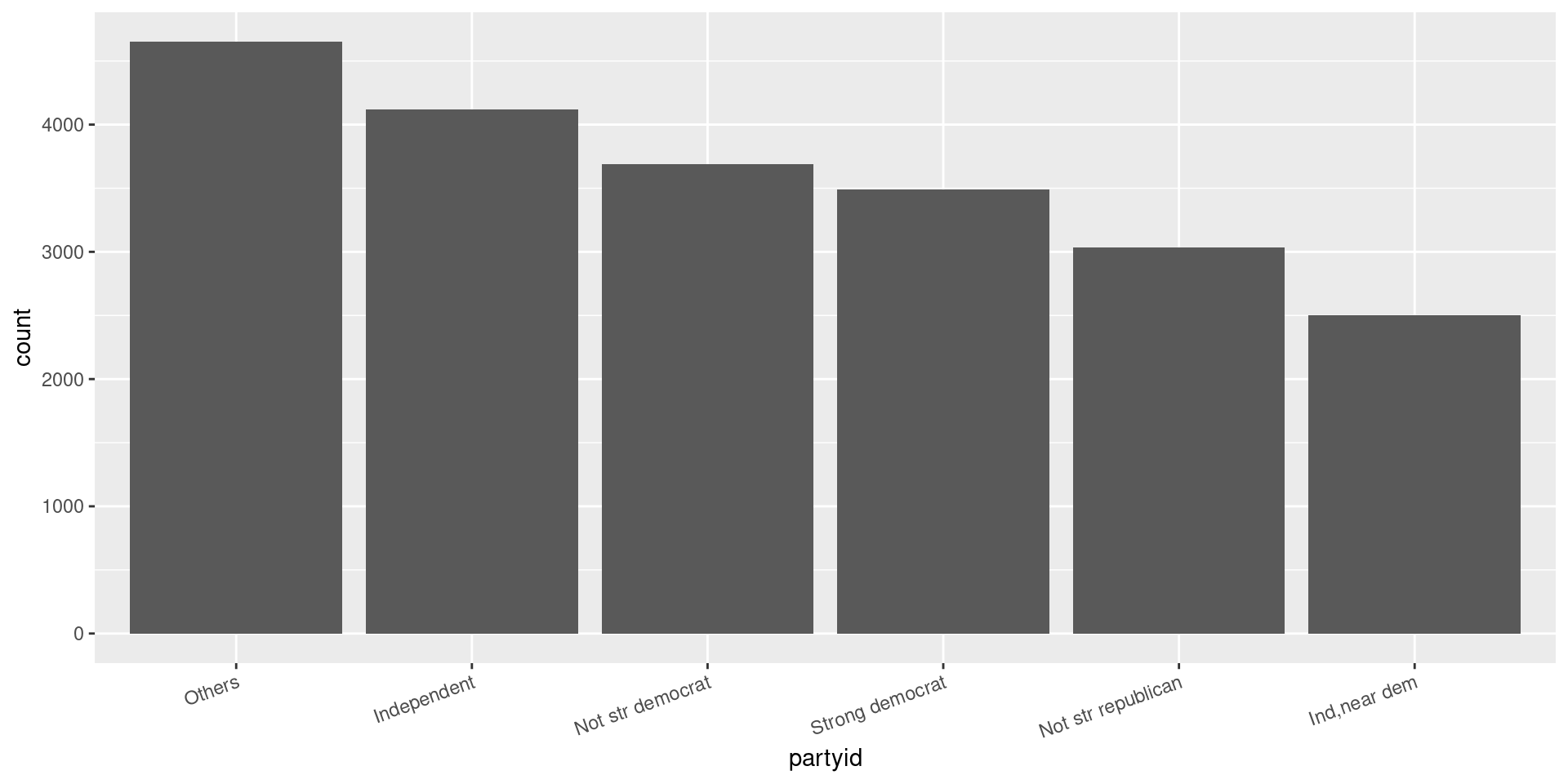
How could we improve the partyid labels?
fct_recode()
gss_cat %>%
drop_na(tvhours) %>%
select(partyid, tvhours) %>%
mutate(partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat")) %>%
group_by(partyid) %>%
summarize(tvhours = mean(tvhours)) %>%
ggplot(aes(tvhours, fct_reorder(partyid, tvhours))) +
geom_point() +
labs(y = "partyid")fct_collapse()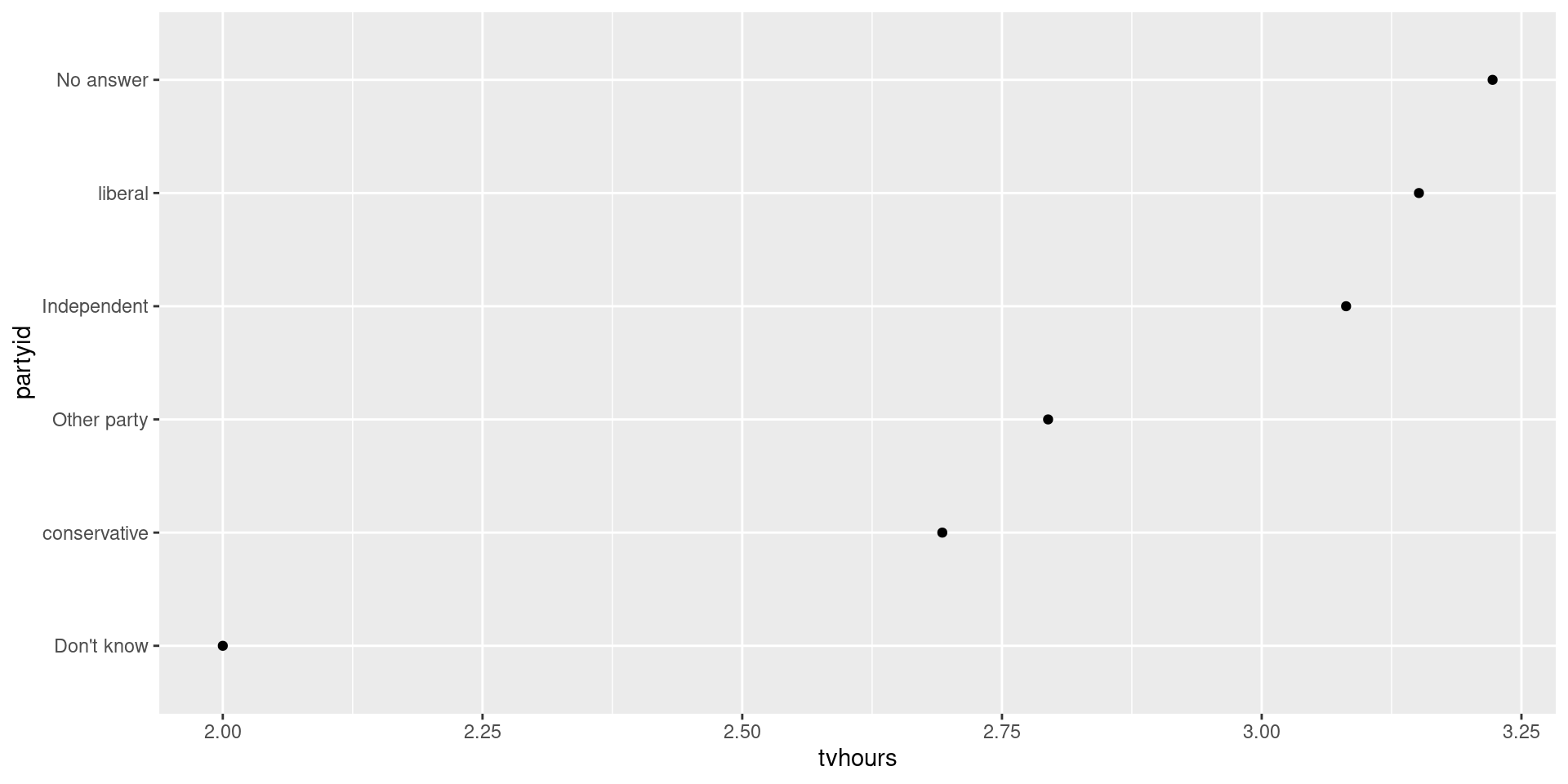
gss_cat %>%
drop_na(tvhours) %>%
select(partyid, tvhours) %>%
mutate(
partyid =
fct_collapse(
partyid,
conservative = c("Strong republican",
"Not str republican",
"Ind,near rep"),
liberal = c("Strong democrat",
"Not str democrat",
"Ind,near dem"))
) %>%
group_by(partyid) %>%
summarize(tvhours = mean(tvhours)) %>%
ggplot(aes(tvhours, fct_reorder(partyid, tvhours))) +
geom_point() +
labs(y = "partyid")fct_lump()
10:00