Model Accuracy and Evaluation
STAT 220
Workflows

A machine learning workflow (the “black box”) containing model specification and preprocessing recipe/formula
Group Activity 1

- Please clone the
ca22-yourusernamerepository from Github - Please do problem 1 in the class activity for today
10:00 How to choose the number of neighbors in a principled way?

We normally don’t have a clear separation between classes and usually have more than 2 features.
Eyeballing on a plot to discern the classes is not very helpful in the practical sense
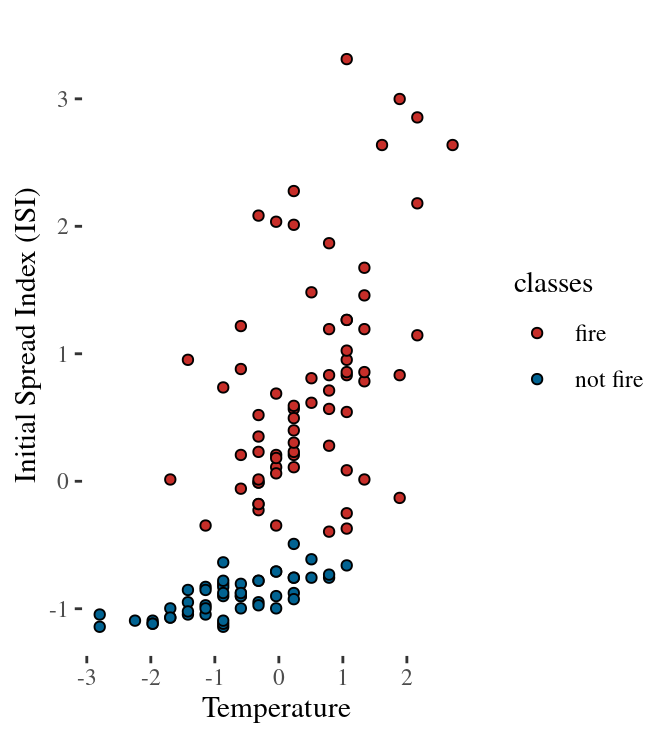
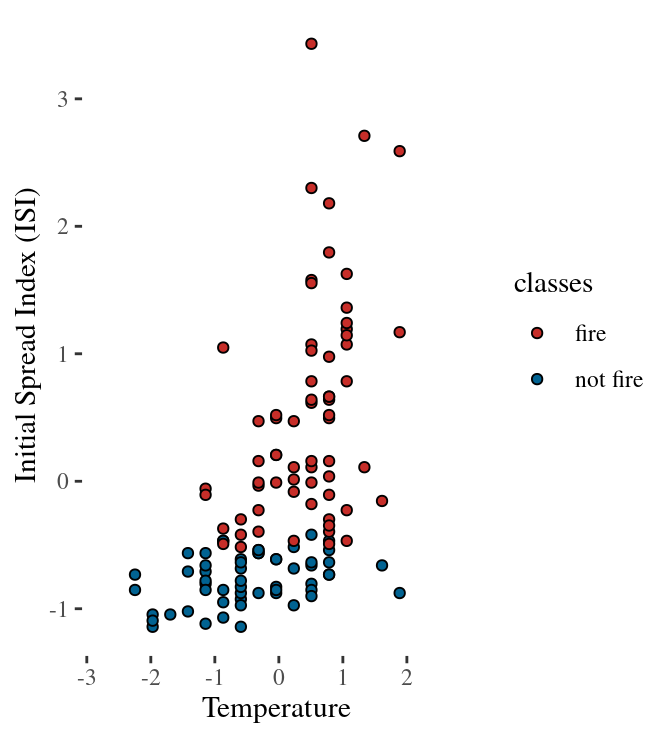
Train (left) and test (right) dataset (50-50)
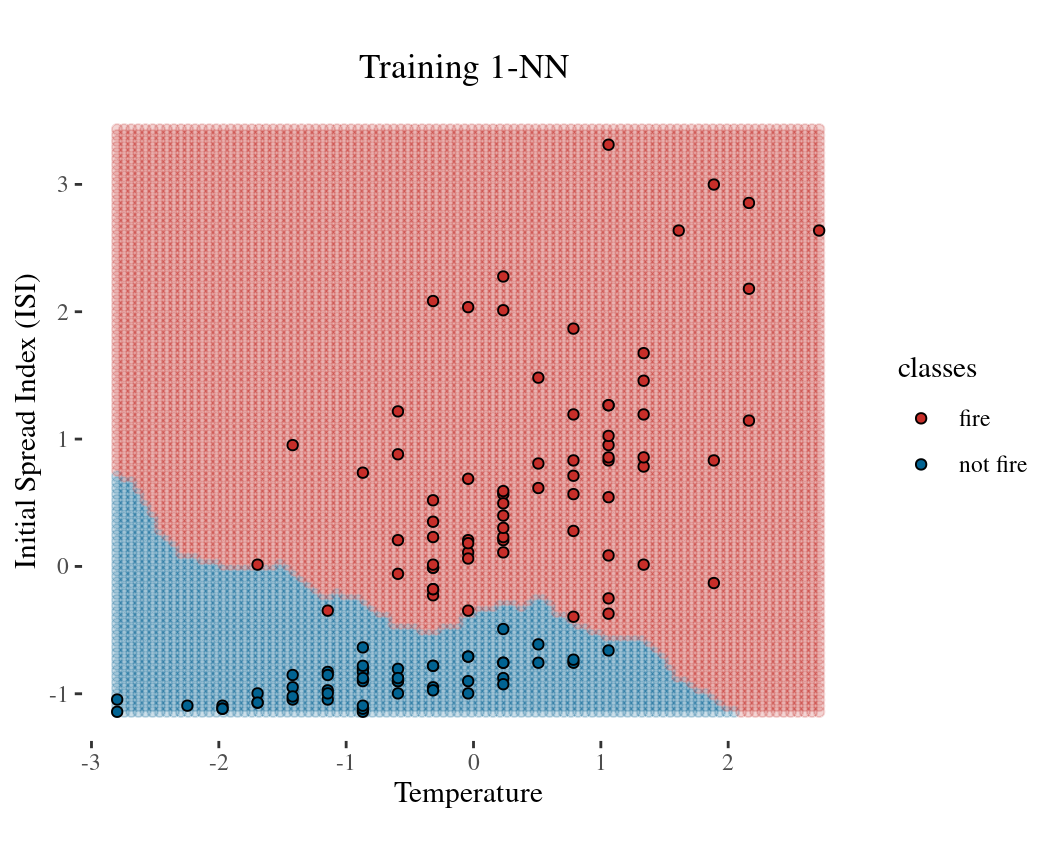
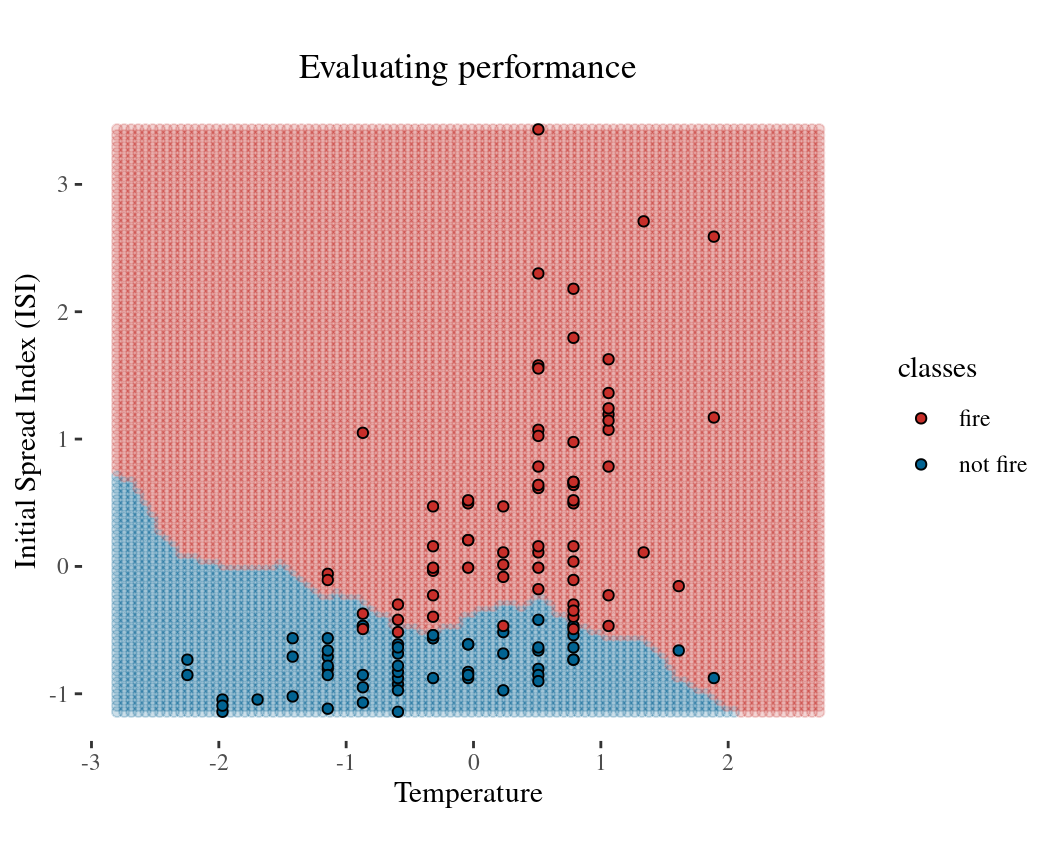
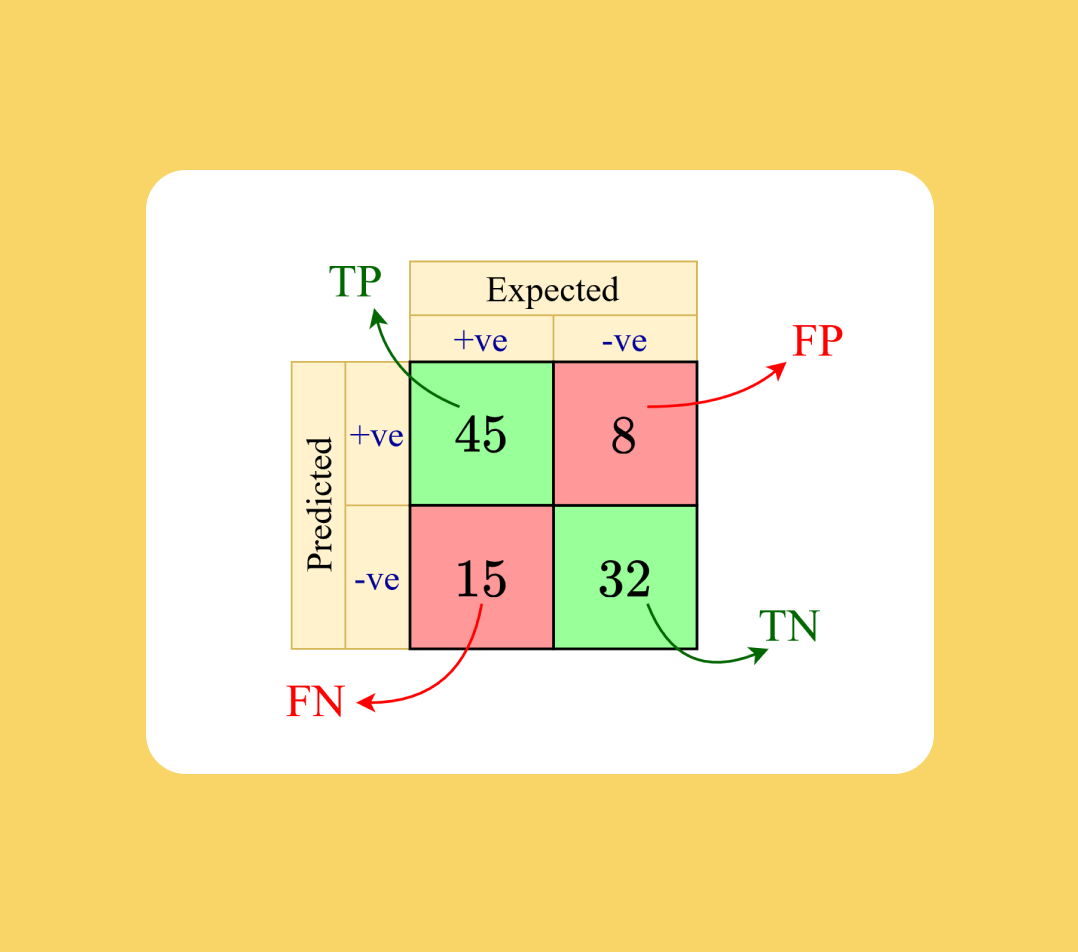
Confusion matrix: tabulation of true (i.e. expected) and predicted class labels
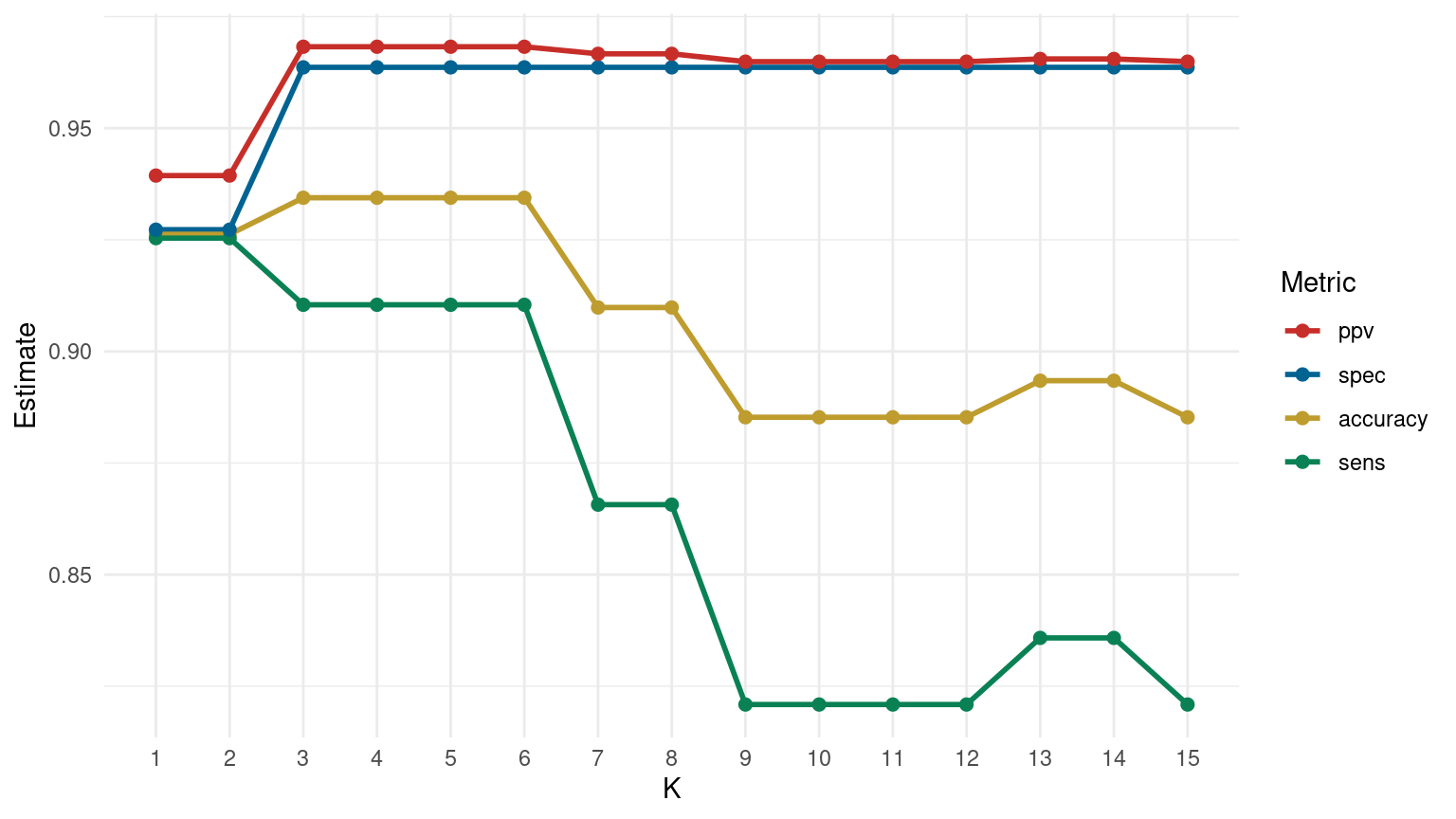
Performance metrics
Group Activity 2
- Please finish the remaining problems in the class activity for today
10:00 Choose the optimal K based on majority of the metrics!
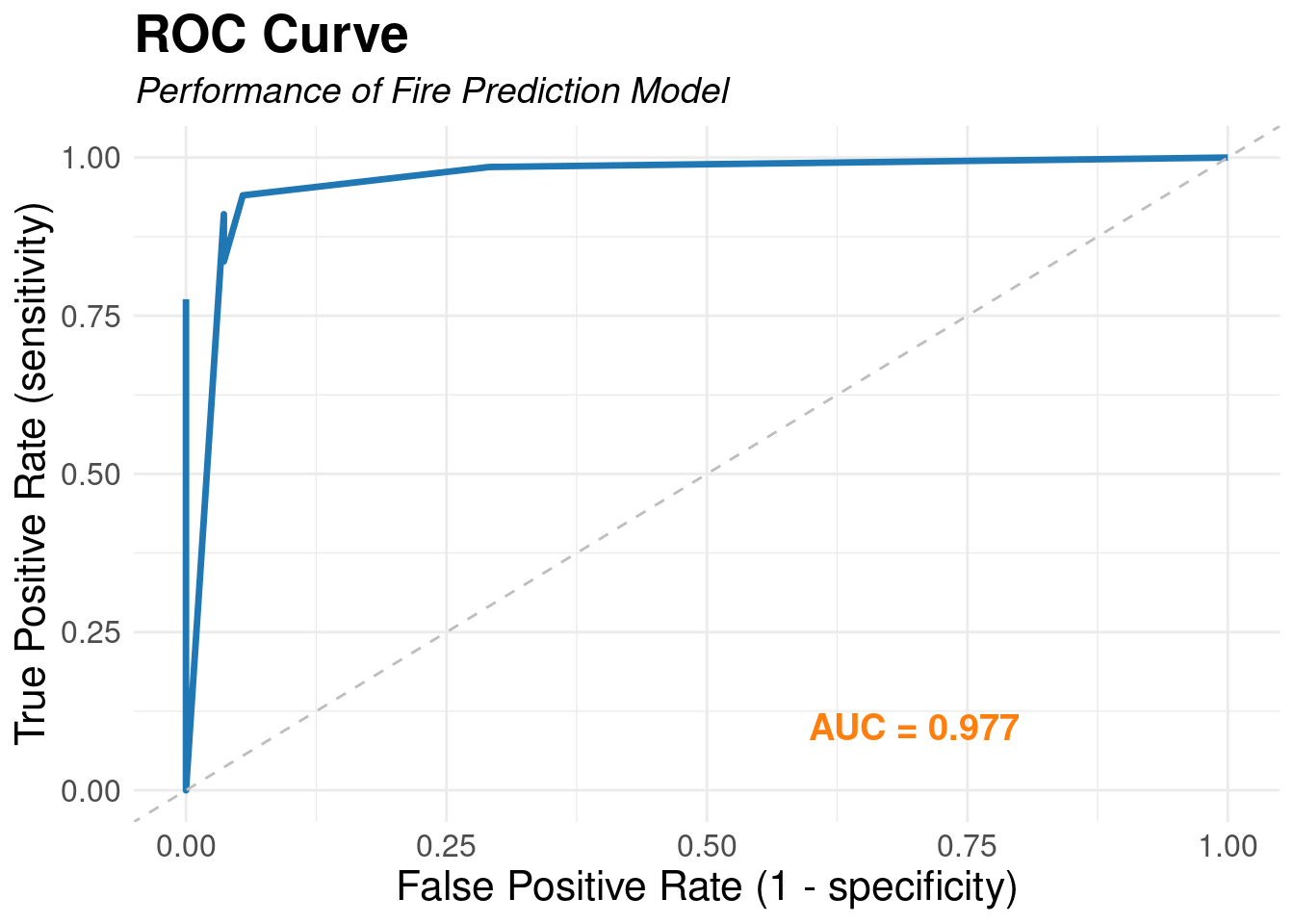
Receiver Operating Characteristic (ROC) curve
library(yardstick)
fire_prob <- predict(fire_knn_fit, test_features, type = "prob")
fire_results2 <- fire_test %>% select(classes) %>% bind_cols(fire_prob)
fire_results2 %>%
roc_curve(truth = classes, .pred_fire) %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_line(color = "#1f77b4", size = 1.2) +
geom_abline(linetype = "dashed", color = "gray") +
annotate("text", x = 0.8, y = 0.1, label = paste("AUC =", round(roc_auc(fire_results2, truth = classes, .pred_fire)$.estimate, 3)), hjust = 1, color = "#ff7f0e", size = 5, fontface = "bold") +
labs(title = "ROC Curve", subtitle = "Performance of Fire Prediction Model", x = "False Positive Rate (1 - specificity)", y = "True Positive Rate (sensitivity)") +
theme_minimal()