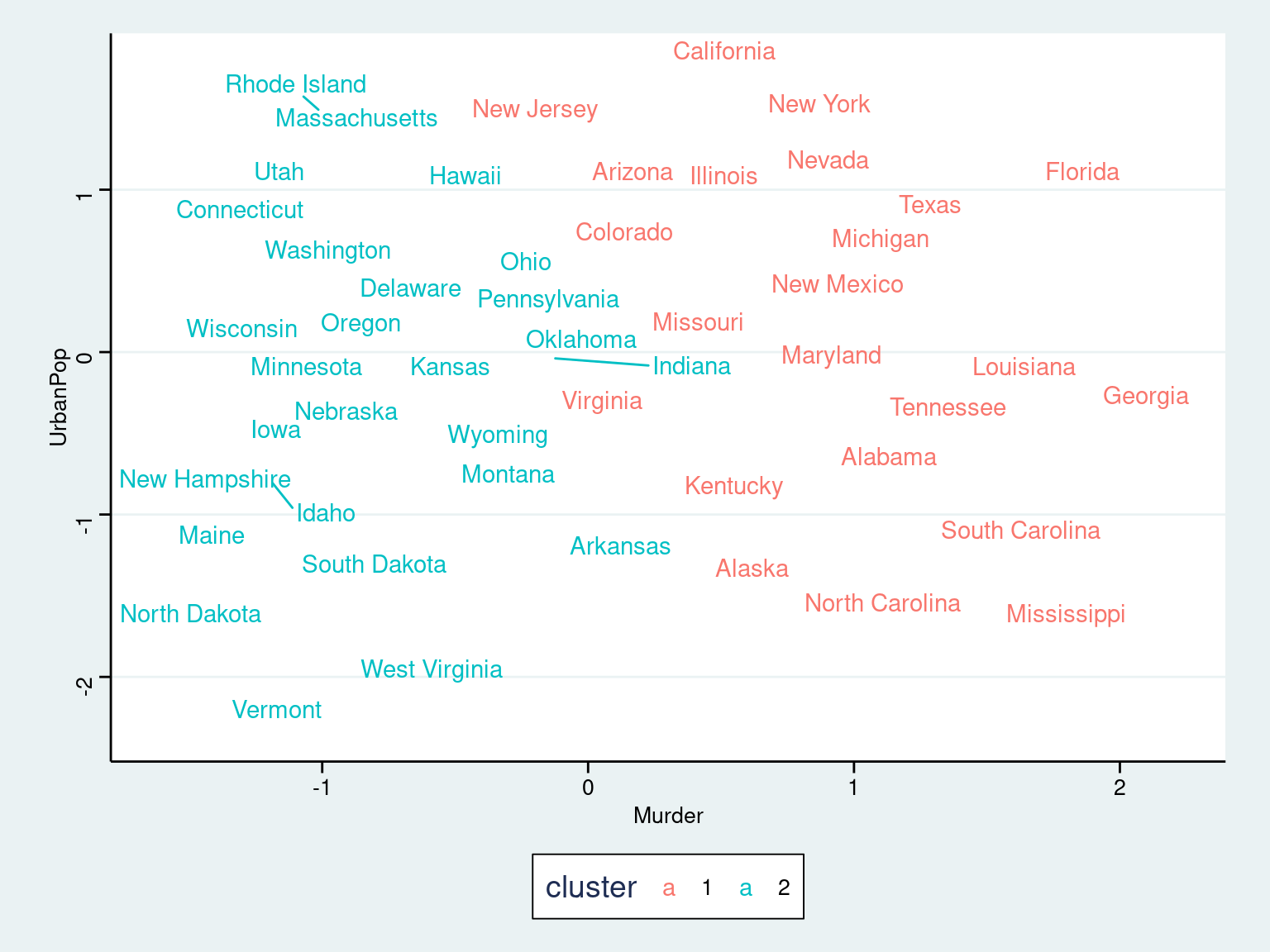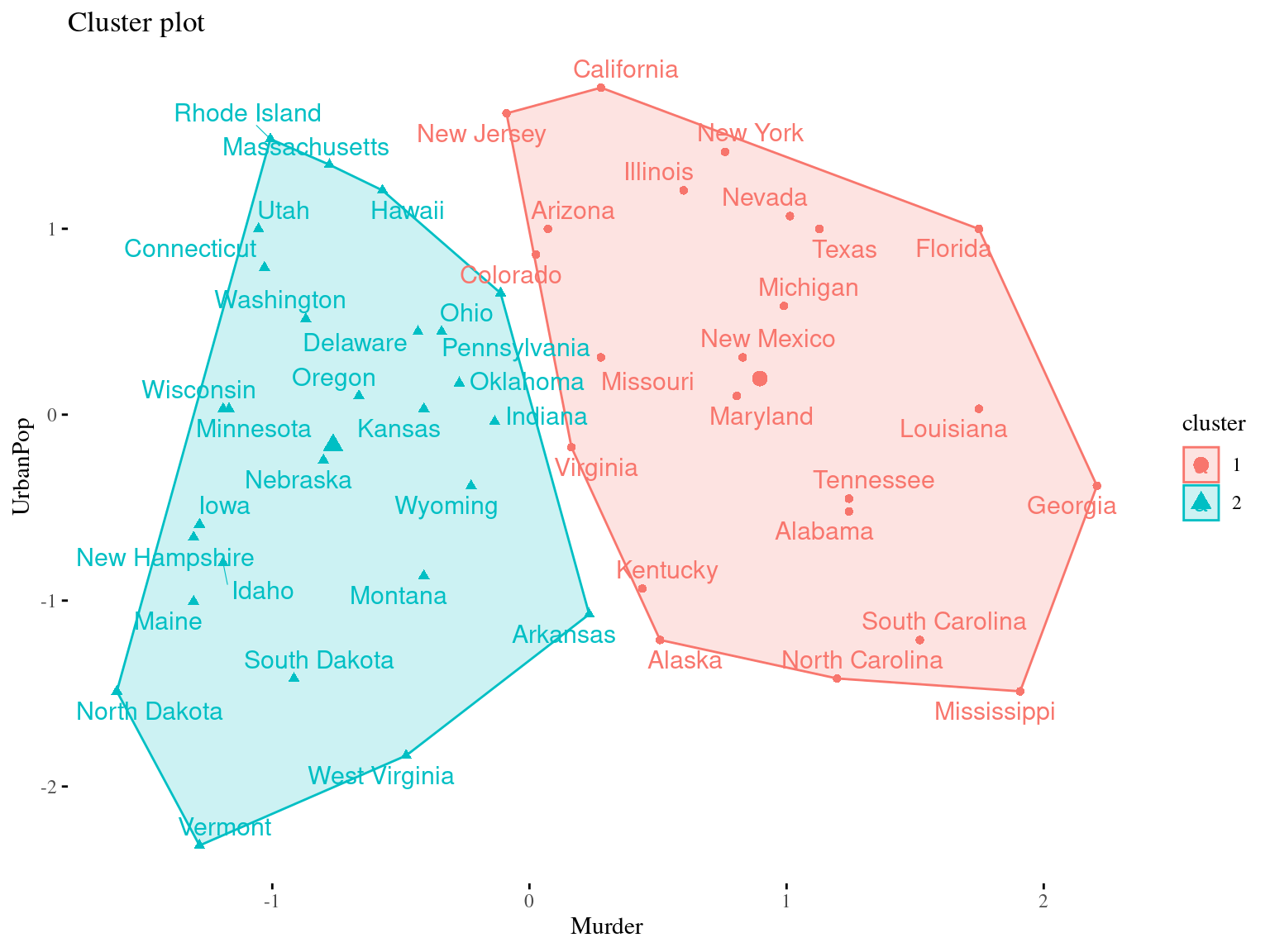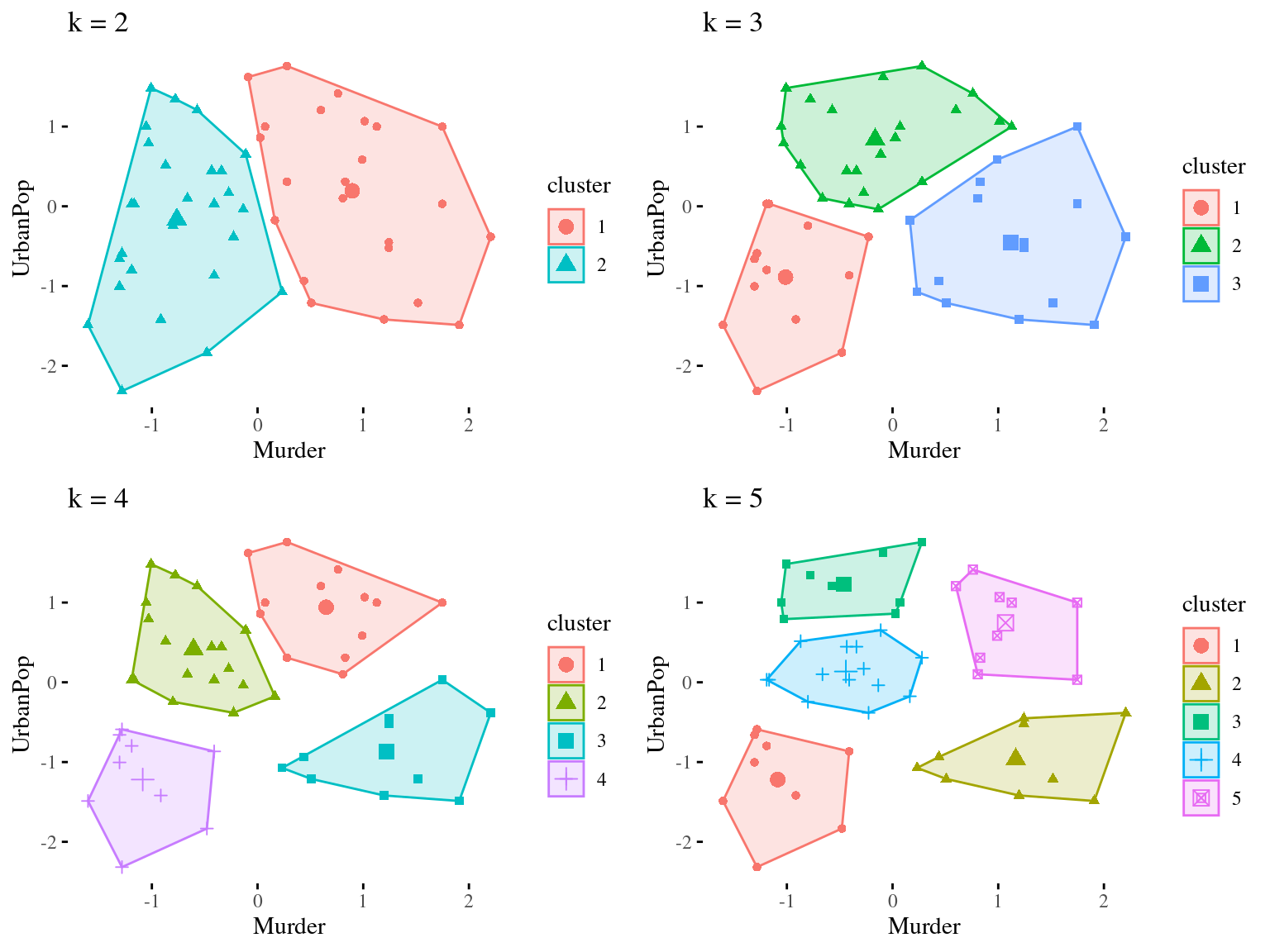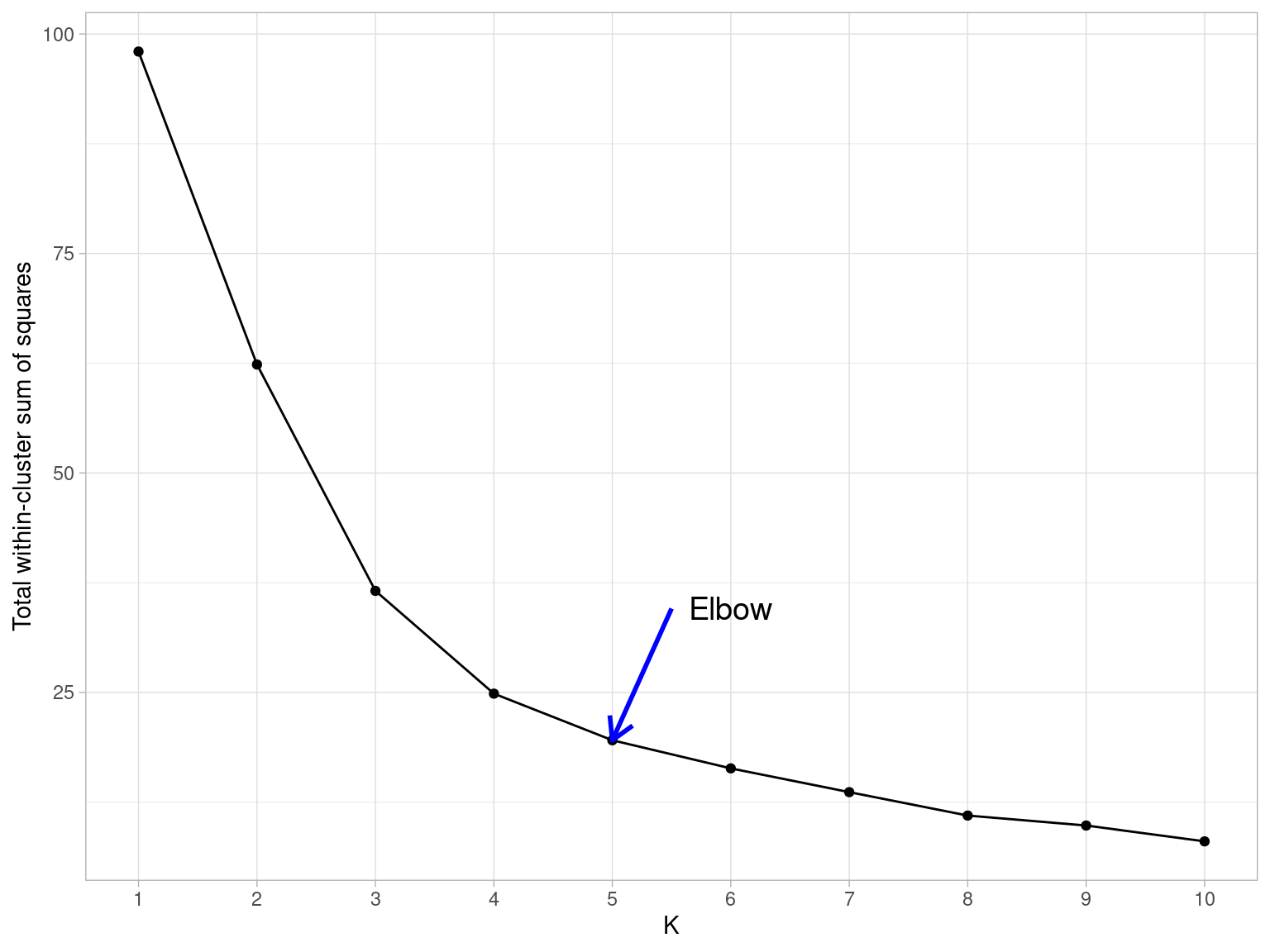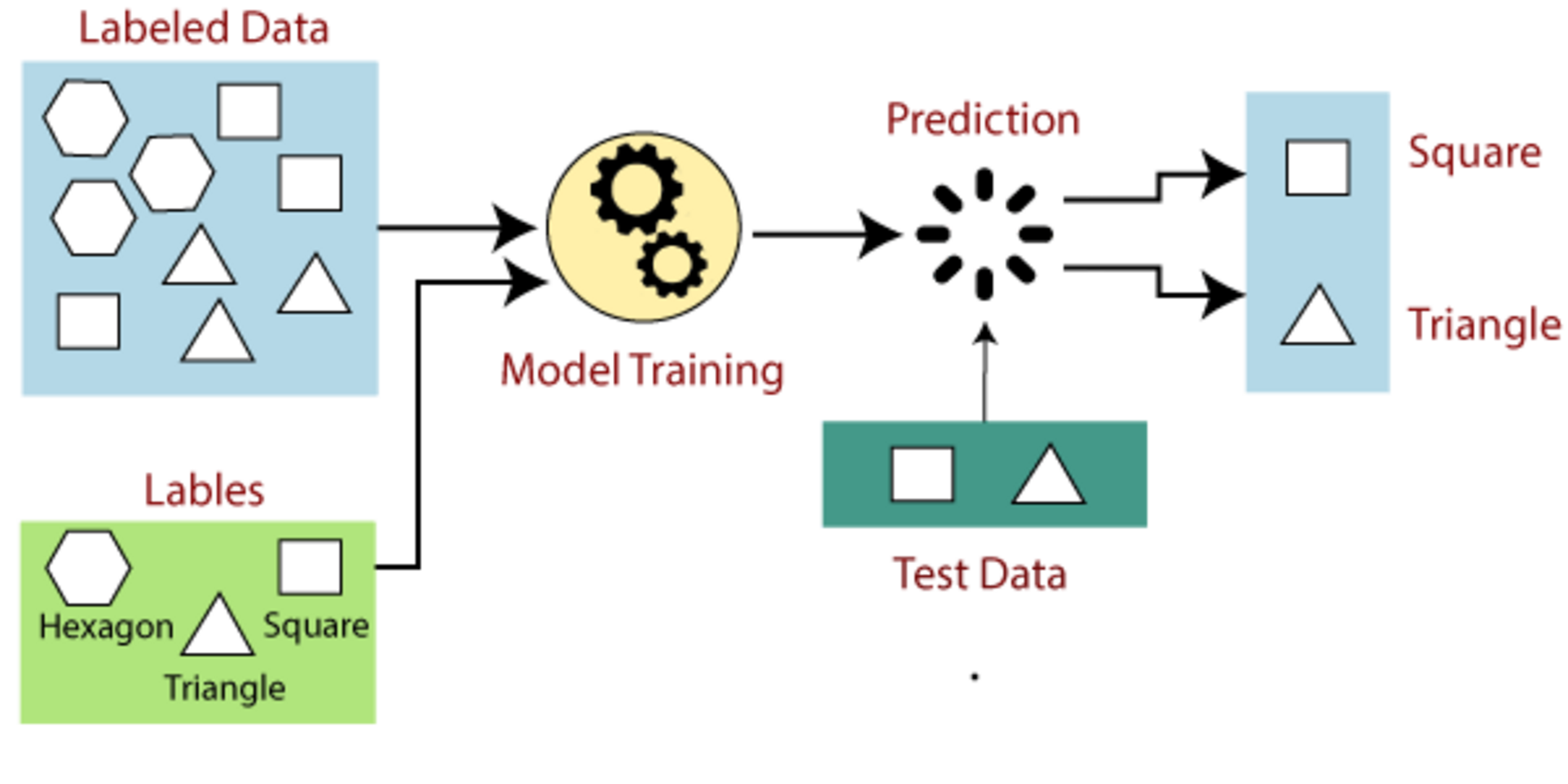
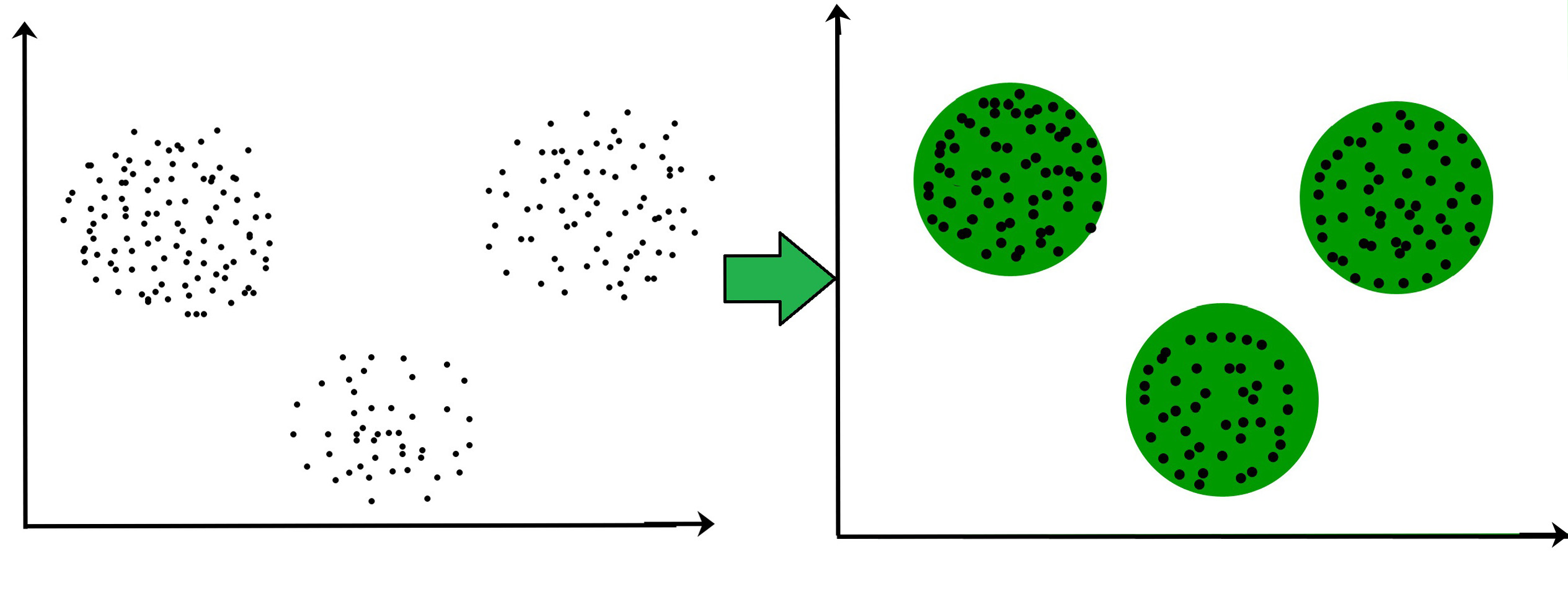
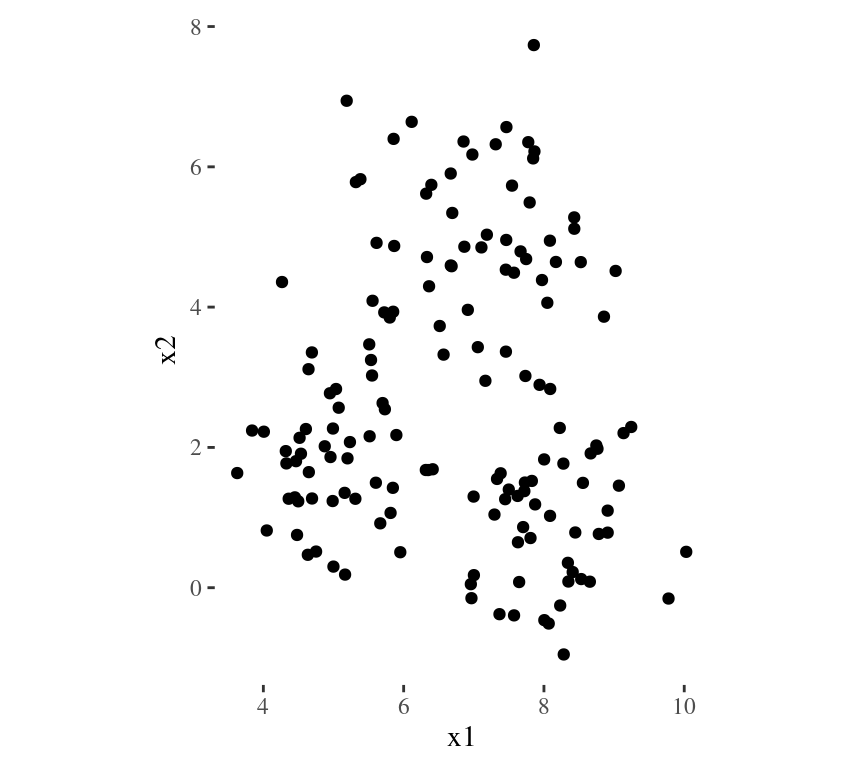
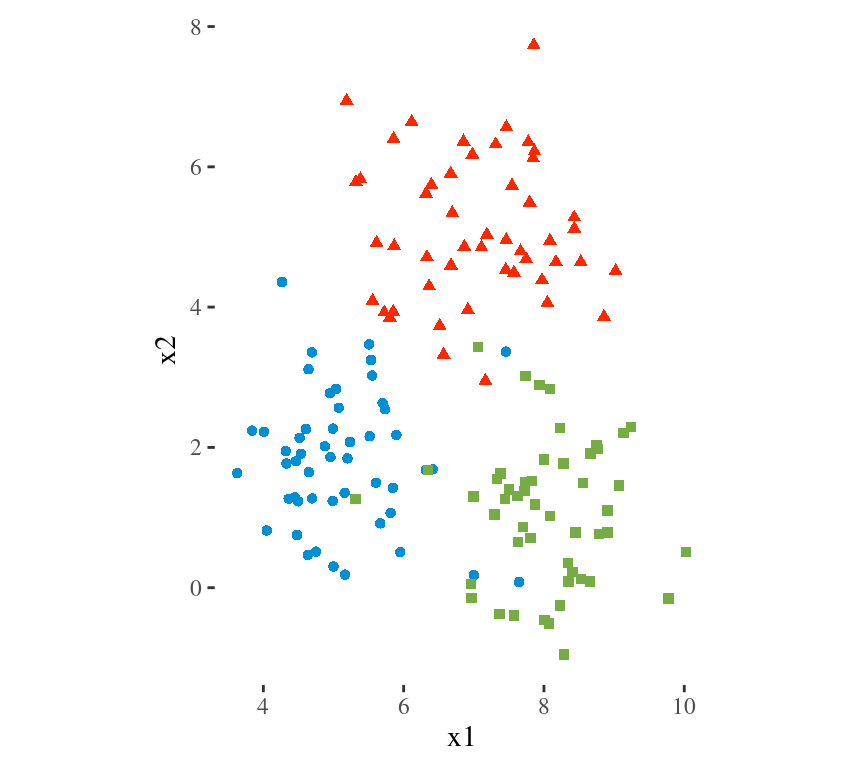
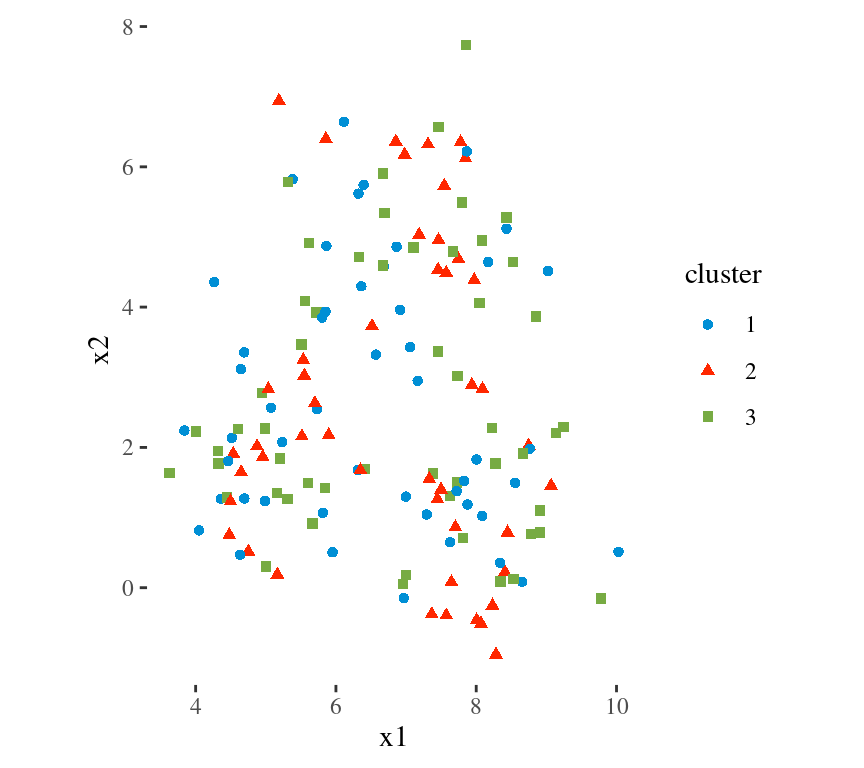
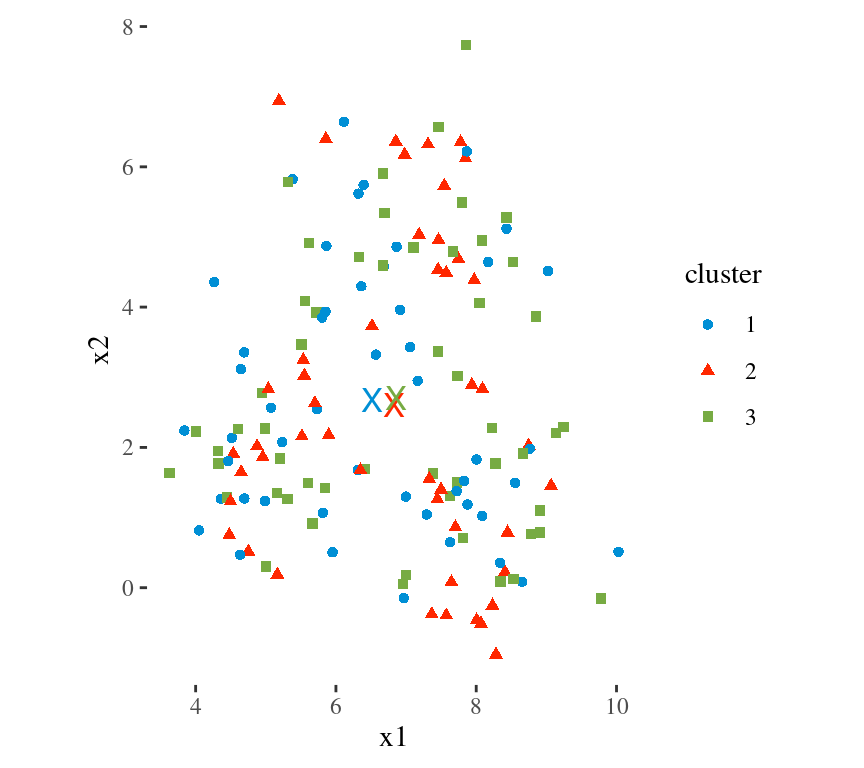
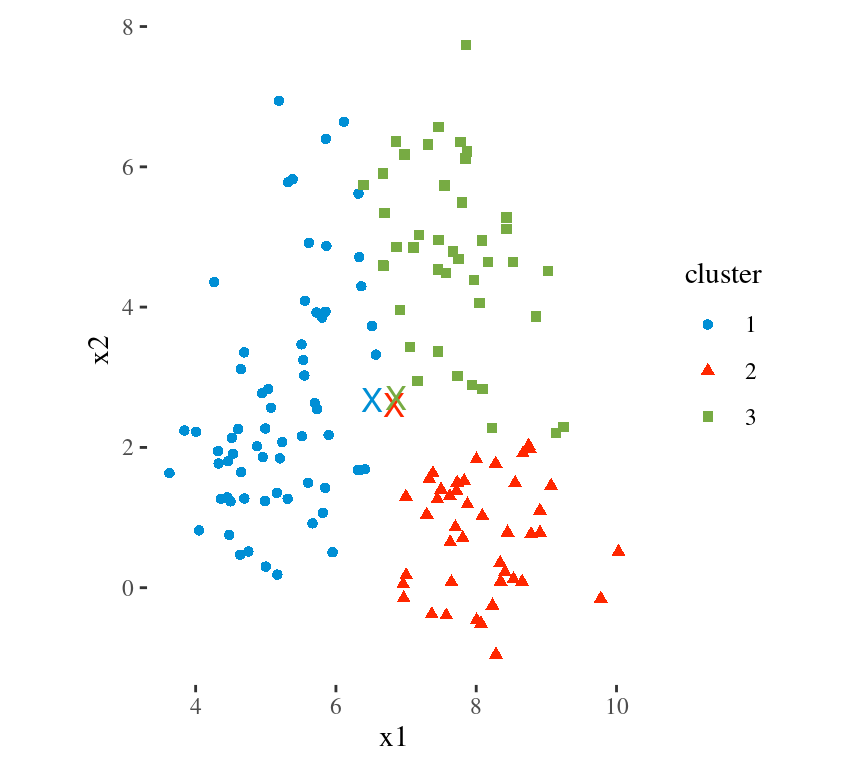
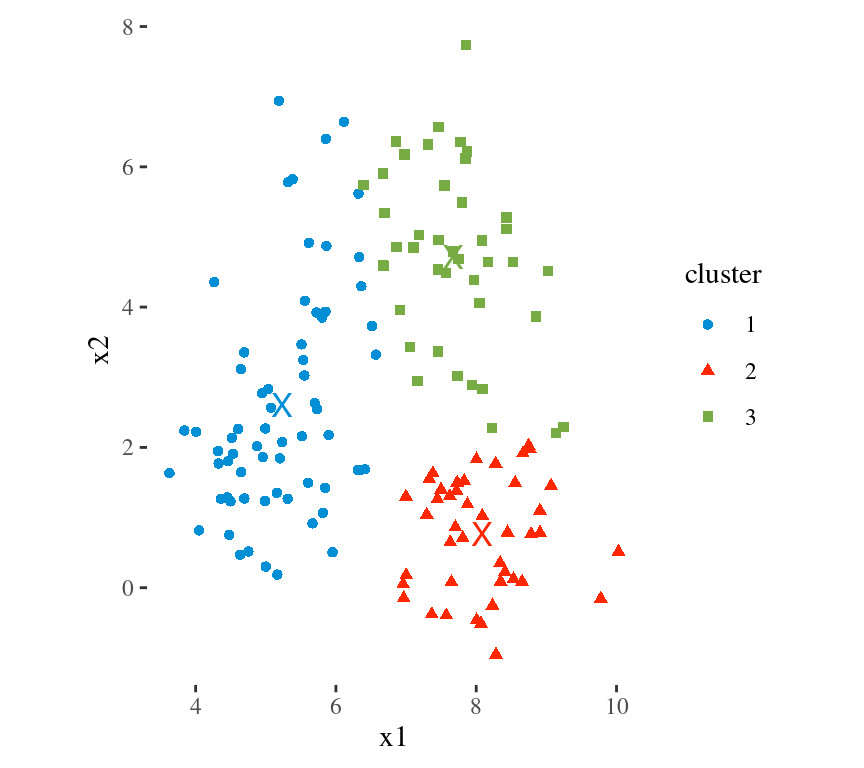
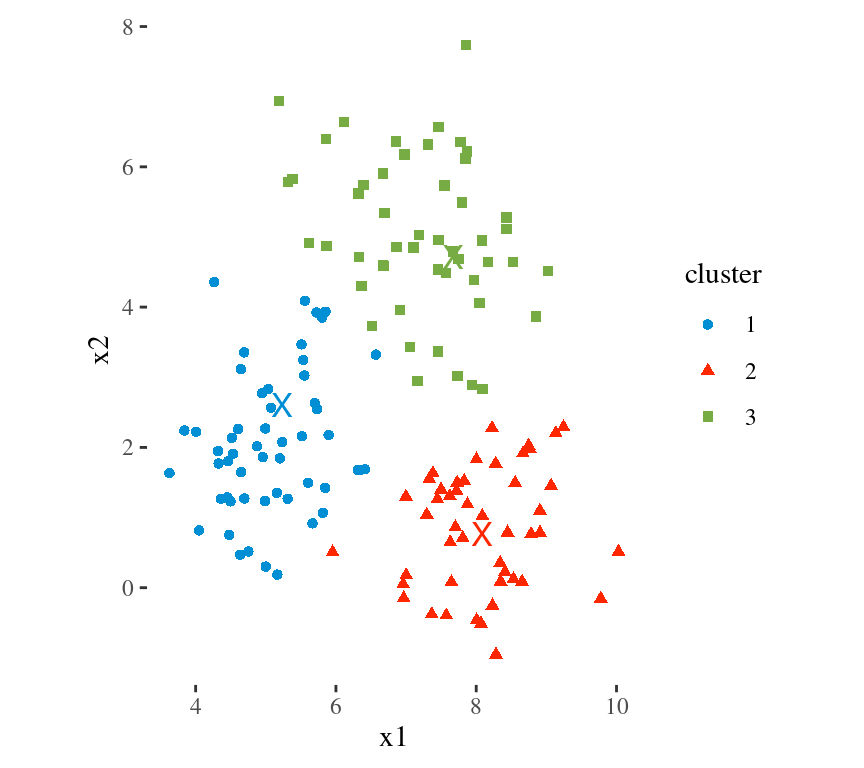
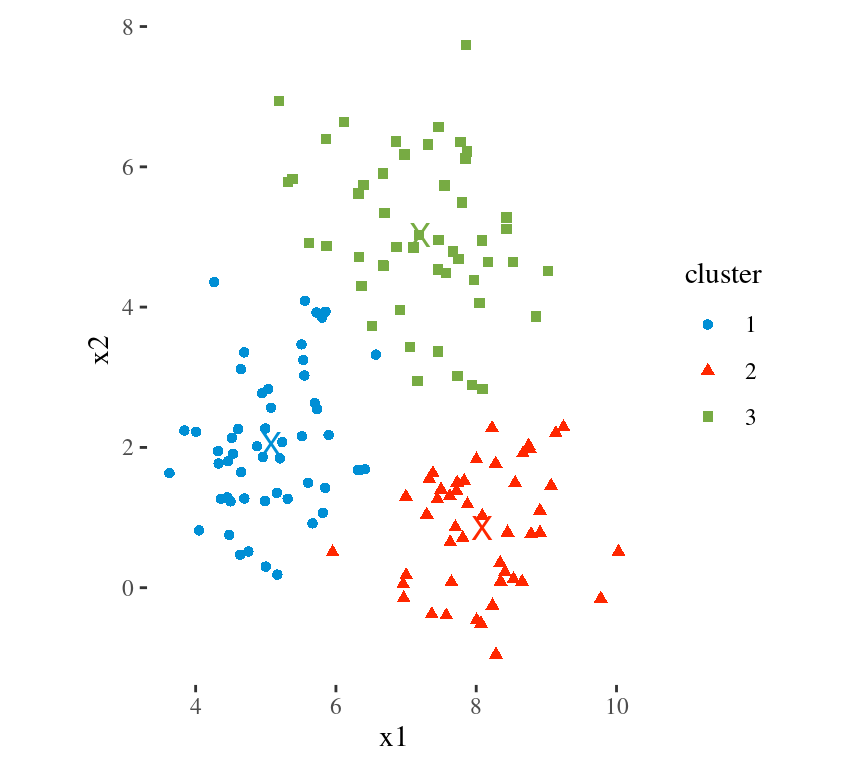
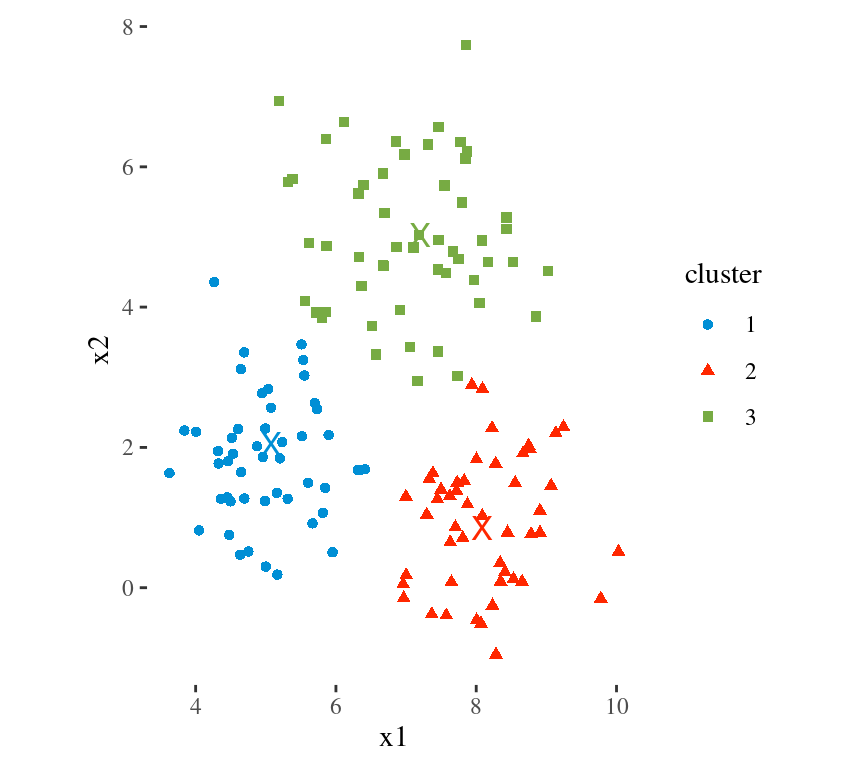
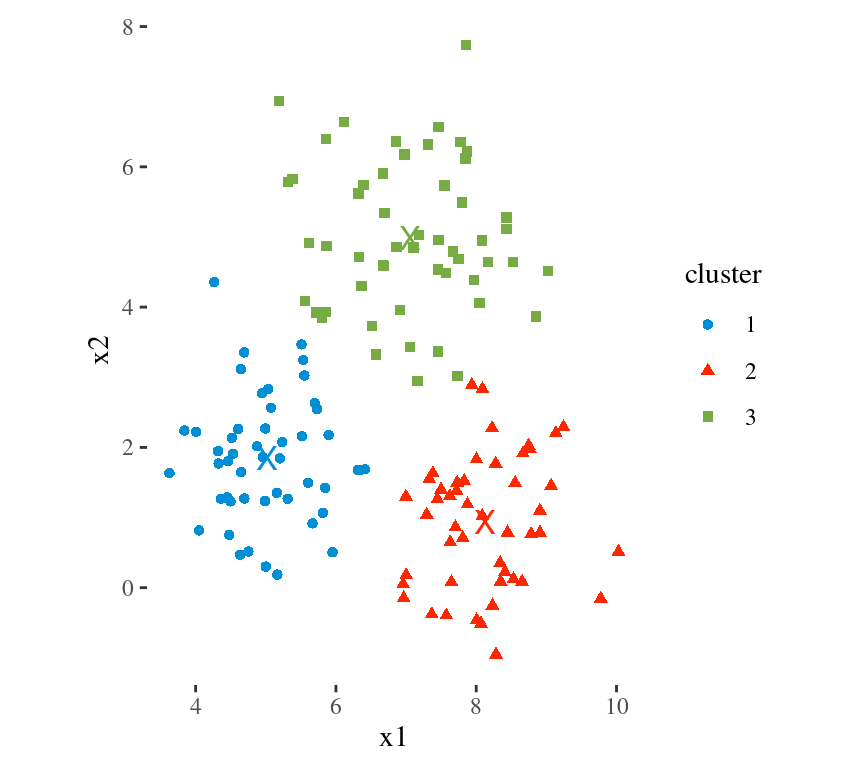
Main Idea
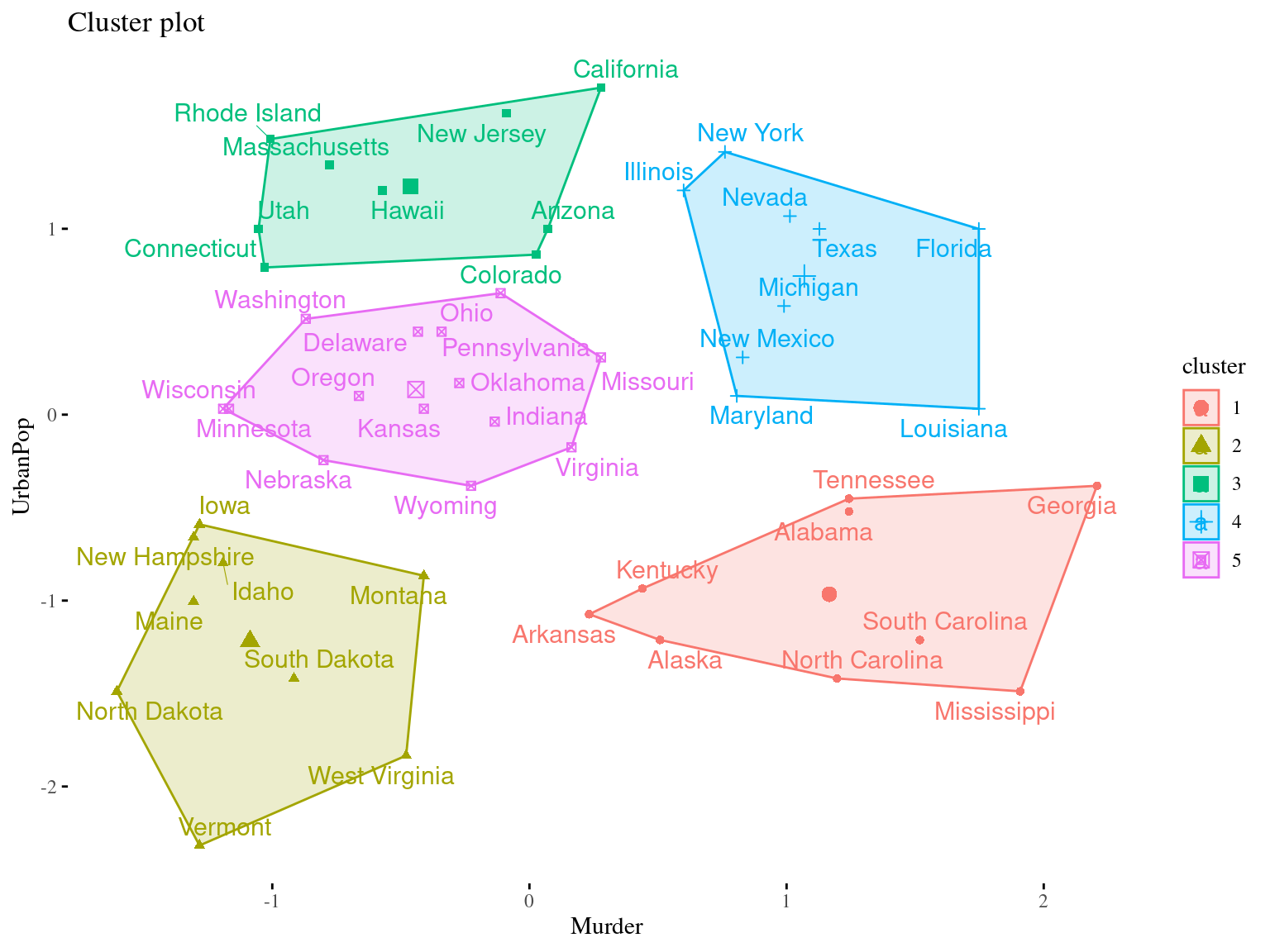
To minimize the total within cluster variation
The total within-cluster variation is the sum of squared Euclidean distances between items and the corresponding centroid:
\[WSS = \sum_{k=1}^K WSS(C_k) = \sum_{k=1}^K \sum_{x_i \in C_k}(x_i - \mu_k)^2\] where:
- WSS is the Within Cluster Sum of Squared Errors
- \(x_i\) is a data point in the cluster \(C_k\)
- \(\mu_k\) is the mean value of the points assigned to the cluster \(C_k\)