# load the necessary libraries
library(tidyverse)
library(tidymodels)
library(yardstick) # extra package for getting metrics
library(parsnip) # tidy interface to models
library(ggthemes)
library(vip)
library(ISLR)
library(rpart.plot)
library(janitor)
library(ranger)
fire <- read_csv("https://raw.githubusercontent.com/deepbas/statdatasets/main/Algeriafires.csv")
fire <- fire %>% clean_names() %>%
drop_na() %>%
mutate_at(c(10,13), as.numeric) %>%
mutate(classes = as.factor(classes)) %>%
select(-year, -day, -month)Class Activity 27
Group Activity 1
Use the fire data set and predict fire using all available predictor variables.
- Split the dataset into training and test set by the proportion \(80\) to \(20\), create a 10 fold cross validation object, and a recipe t0 preprocess the data.
Click for answer
Answer:
set.seed(314) # Remember to always set your seed.
fire_split <- initial_split(fire, prop = 0.80, strata = classes)
fire_train <- fire_split %>% training()
fire_test <- fire_split %>% testing()
# Create folds for cross validation on the training data set
fire_folds <- vfold_cv(fire_train, v = 10, strata = classes)
fire_recipe <- recipe(classes ~ ., data = fire_train) %>%
step_dummy(all_nominal(), -all_outcomes()) - Specify a decision tree classification model with
rpartcomputational engine. Prepare the model for tuning (i.e., fitting with a range of parameters for validation purposes).
Click for answer
Answer:
tree_model <- decision_tree(cost_complexity = tune(),
tree_depth = tune(),
min_n = tune()) %>%
set_engine('rpart') %>%
set_mode('classification')- Combine the model and recipe into a workflow to easily manage the model-building process.
Click for answer
Answer:
tree_workflow <- workflow() %>%
add_model(tree_model) %>%
add_recipe(fire_recipe)- Create a grid of hyper-parameter values to test
Click for answer
Answer:
tree_grid <- grid_random(cost_complexity(),
tree_depth(),
min_n(),
size = 10)- Tune decision tree workflow
Click for answer
Answer:
set.seed(314)
tree_tuning <- tree_workflow %>%
tune_grid(resamples = fire_folds,
grid = tree_grid)- Show the best models under the accuracy criteria.
Click for answer
Answer:
tree_tuning %>% show_best(metric = 'accuracy')# A tibble: 5 × 9
cost_complexity tree_depth min_n .metric .estimator mean n std_err
<dbl> <int> <int> <chr> <chr> <dbl> <int> <dbl>
1 6.85e- 8 9 2 accuracy binary 0.974 10 0.0118
2 1.37e-10 6 3 accuracy binary 0.968 10 0.0143
3 5.22e- 3 3 18 accuracy binary 0.963 10 0.0161
4 1.03e- 4 11 26 accuracy binary 0.963 10 0.0161
5 5.77e- 3 6 33 accuracy binary 0.963 10 0.0161
# ℹ 1 more variable: .config <chr>- Select best model based on accuracy and view the best parameters. What is the corresponding tree depth?
Click for answer
Answer:
best_tree <- tree_tuning %>% select_best(metric = 'accuracy')
best_tree# A tibble: 1 × 4
cost_complexity tree_depth min_n .config
<dbl> <int> <int> <chr>
1 0.0000000685 9 2 Preprocessor1_Model04- Using the
best_treeobject, finalize the workflow usingfinalize_workflow().
Click for answer
Answer:
final_tree_workflow <- tree_workflow %>% finalize_workflow(best_tree)- Fit the train data to the finalized workflow and extract the fit.
Click for answer
Answer:
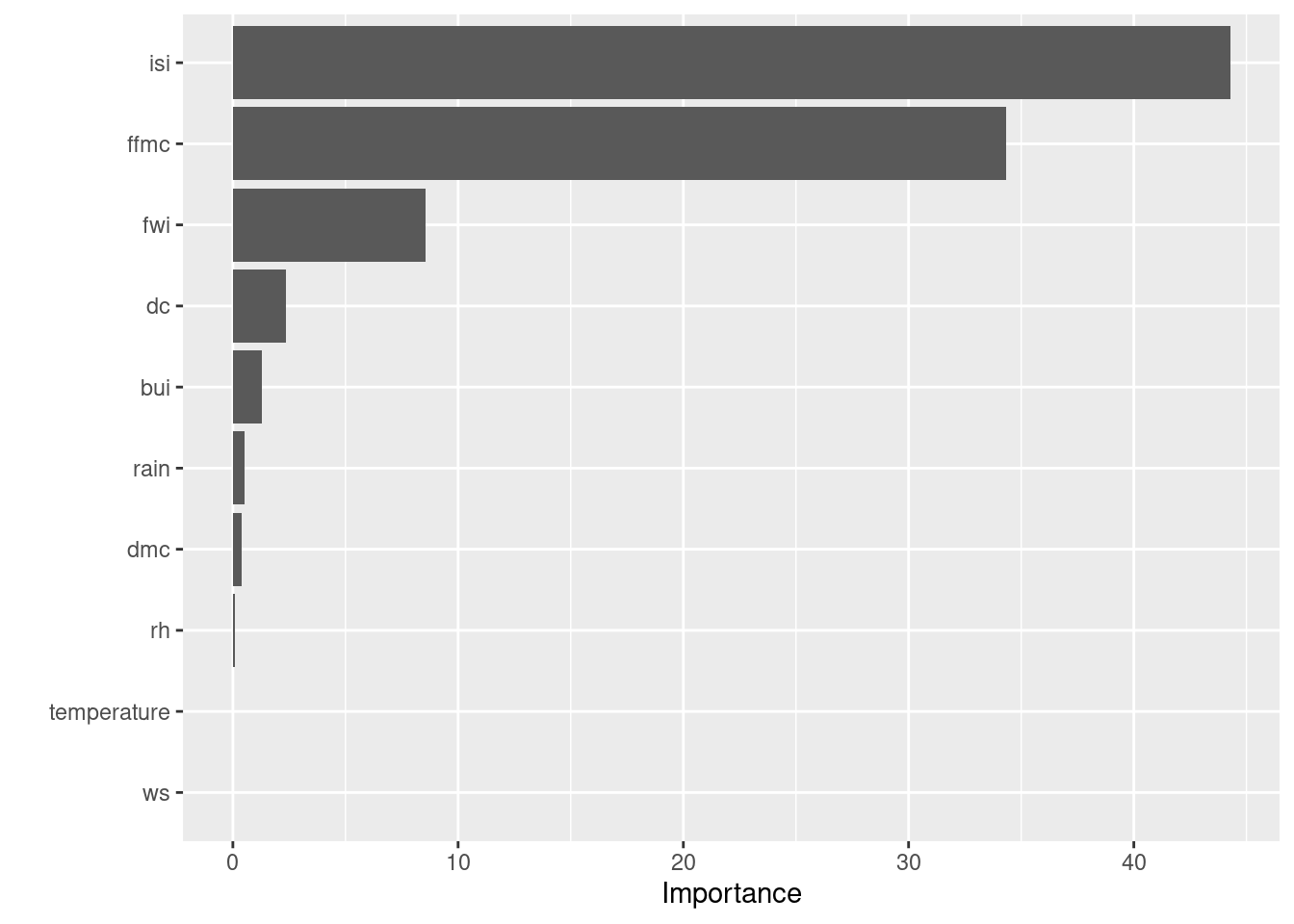
tree_wf_fit <- final_tree_workflow %>% fit(data = fire_train)tree_fit <- tree_wf_fit %>% extract_fit_parsnip()- Construct variable importance plot. What can you conclude from this plot?
Click for answer
Answer:
vip(tree_fit) 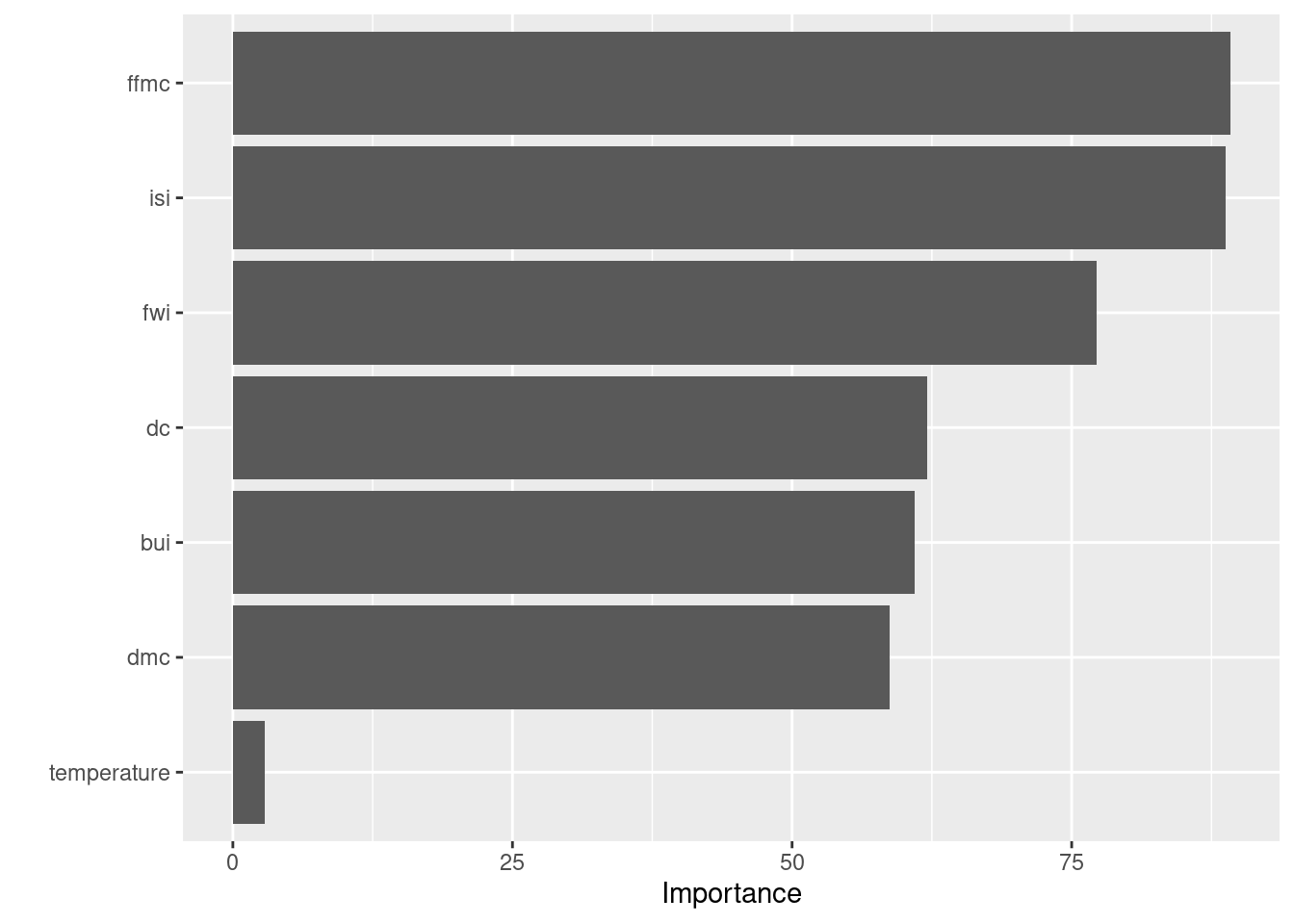
# Bars with different colors
vi_data <- vi(tree_fit)
vi_data$Variable <- fct_reorder(vi_data$Variable, vi_data$Importance)
ggplot(vi_data, aes(x = Variable, y = Importance, fill = Variable)) +
geom_col(aes(fill = Variable)) +
scale_fill_viridis_d(option = "rocket", direction = -1) +
labs(title = "Variable Importance", x = "Variables", y = "Importance") +
theme_minimal() +
coord_flip()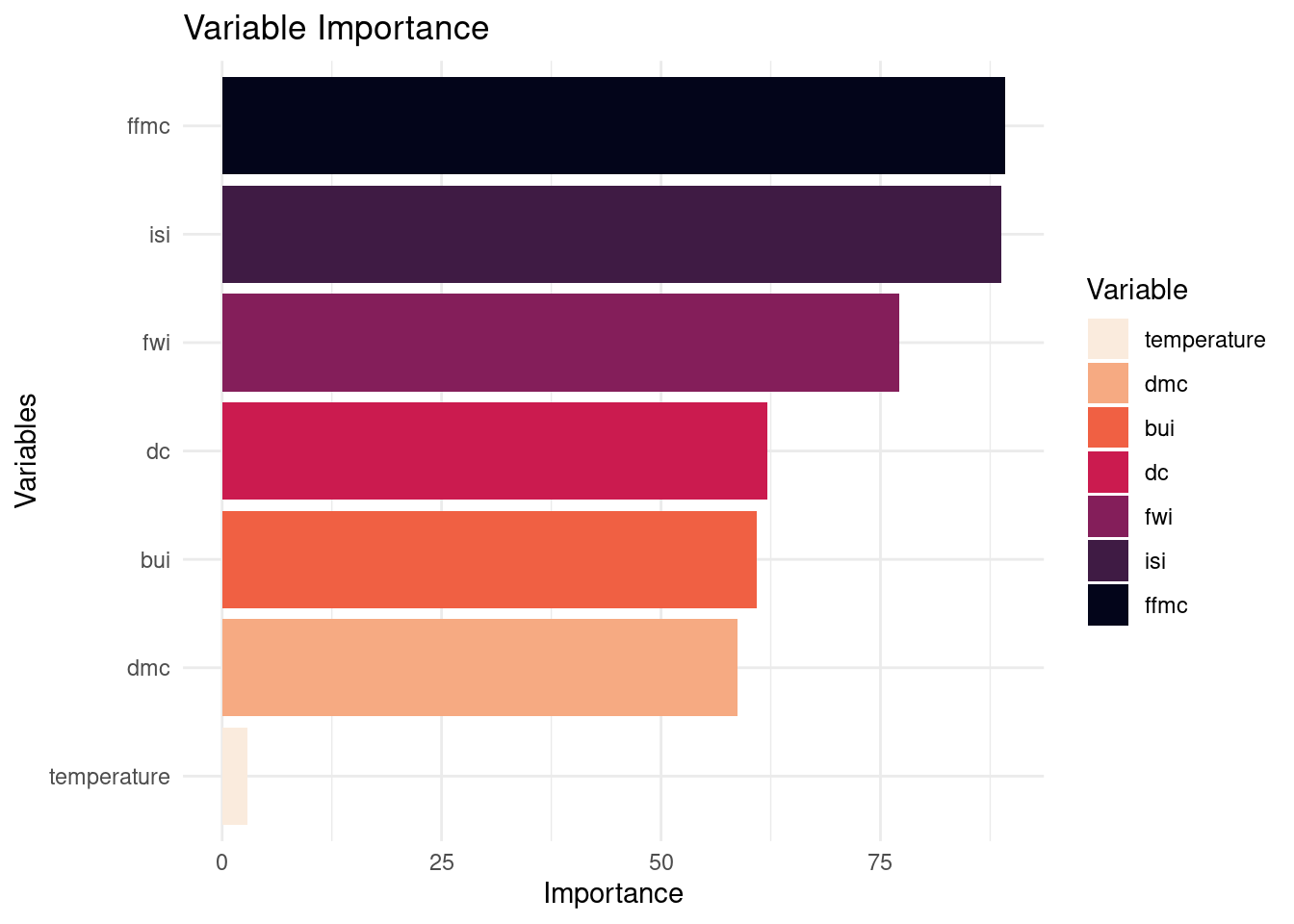
- Construct a decision tree. What do you see in this plot?
Click for answer
Answer:
rpart.plot(tree_fit$fit, roundint = FALSE)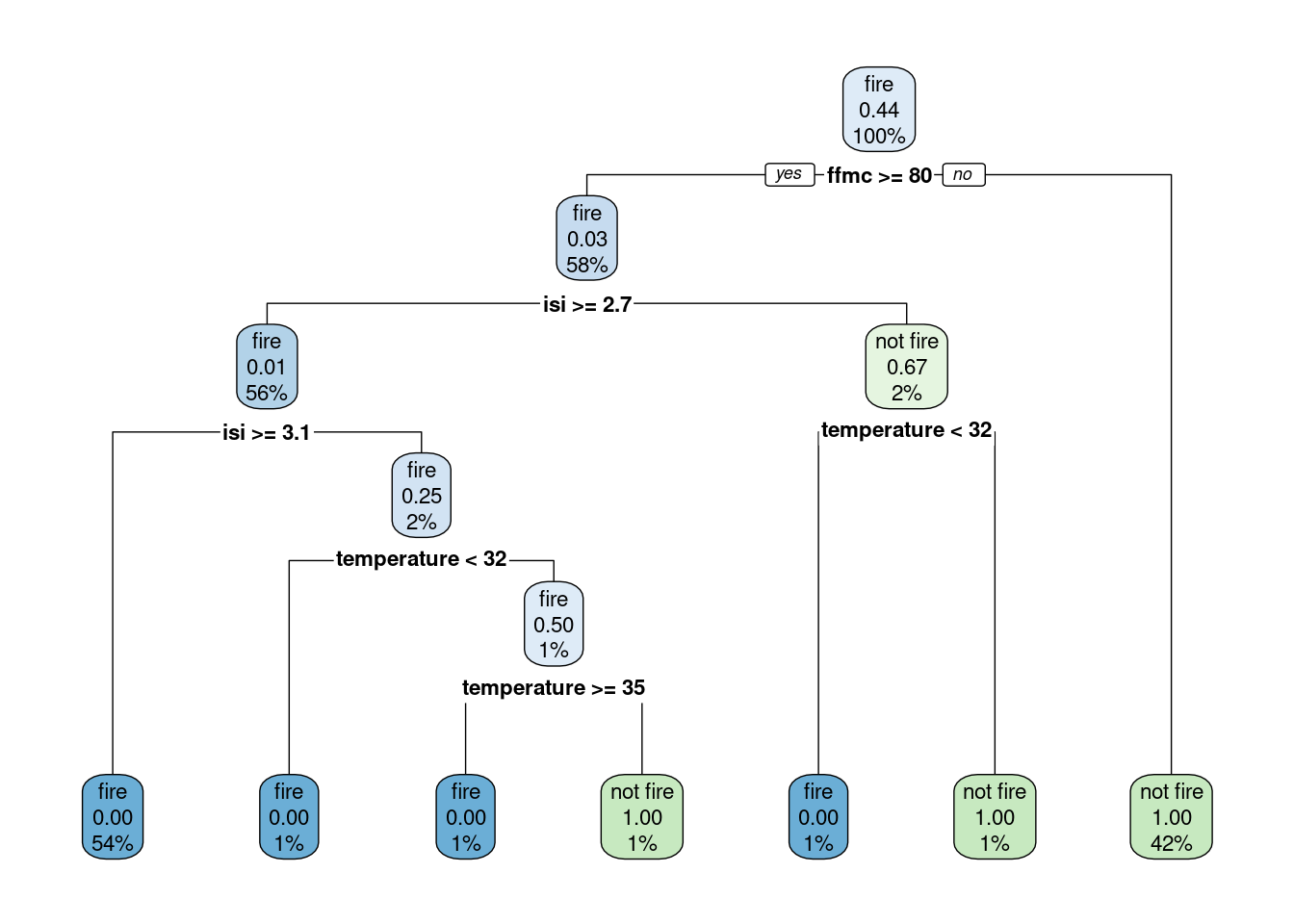
Group Activity 2
Use the fire dataset again to fit a random forest algorithm to produce optimal set of variables used in predicting fire. Use the same recipe defined earlier in group activity 1.
- Specify a decision tree classification model with
rangercomputational engine andimpurityfor variable importance. Prepare the model for tuning (i.e., fitting with a range of parameters for validation purposes).
Click for answer
Answer:
rf_model <- rand_forest(mtry = tune(),
trees = tune(),
min_n = tune()) %>%
set_engine('ranger', importance = "impurity") %>%
set_mode('classification')- Define a workflow object.
Click for answer
Answer:
rf_workflow <- workflow() %>%
add_model(rf_model) %>%
add_recipe(fire_recipe)- Create a grid of hyper parameter values to test. Try different values.
Click for answer
Answer:
rf_grid <- grid_random(mtry() %>% range_set(c(1, 8)),
trees(),
min_n(),
size = 10)- Tune the random forest workflow. Use the
fire_foldsobject from before with 10 cross validation routine.
Click for answer
Answer:
rf_tuning <- rf_workflow %>%
tune_grid(resamples = fire_folds,
grid = rf_grid)- Select the best model based on accuracy.
Click for answer
Answer:
best_rf <- rf_tuning %>%
select_best(metric = 'accuracy')- Finalize the workflow, fit the model, and extract the parameters.
Click for answer
Answer:
final_rf_workflow <- rf_workflow %>%
finalize_workflow(best_rf)
rf_wf_fit <- final_rf_workflow %>%
fit(data = fire_train)
rf_fit <- rf_wf_fit %>%
extract_fit_parsnip()- Plot the variable importance. What can you conclude from this plot?
Click for answer
Answer:
vip(rf_fit)